InnoDB体系架构
InnoDB是MySQL数据库中最常用的存储引擎,InnoDB的体系架构如下图所示: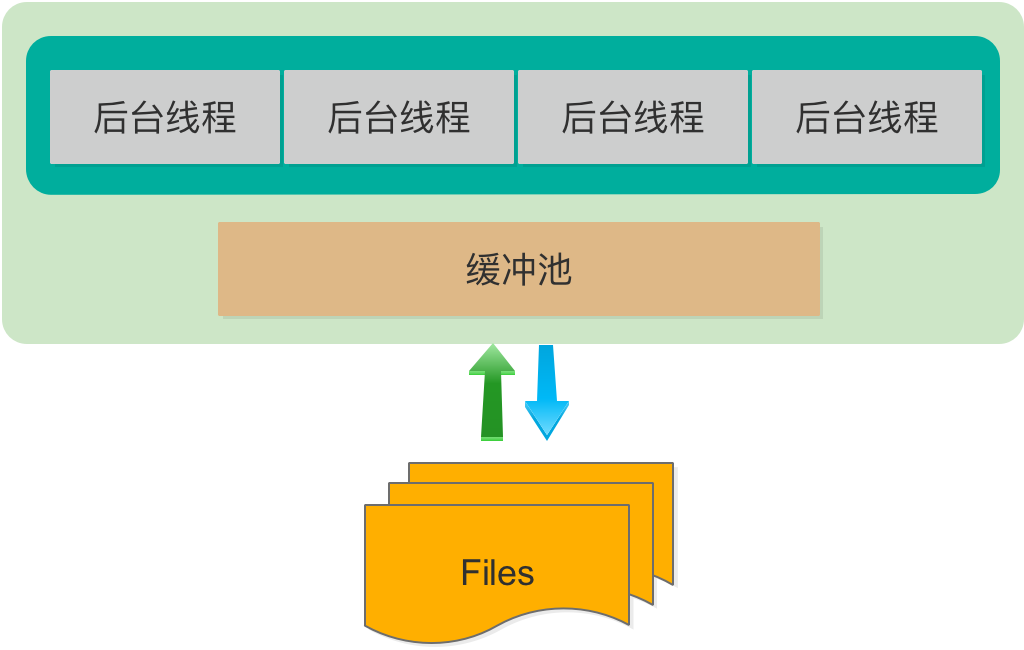
InnoDB体系架构主要包含三部分:后台线程,缓冲池,文件。
(一)后台线程
InnoDB使用多线程模型,后台线程主要分为四个线程:
- Master Thread:
最核心的一个线程,用于异步刷新缓冲页到磁盘,保证数据一致性; - IO Thread:
InnoDB中使用了大量异步IO来处理IO请求,该线程主要负责这些IO请求的回调; - Purge Thread:
该线程用来回收无用的undo页,InnoDB支持多个Purge线程回收undo页; - Page Cleaner Thread:
负责脏页刷新到磁盘的操作,异步刷新;
(二)缓冲池
InnoDB存储引擎是基于磁盘存储的,由于磁盘和CPU之间速度的鸿沟,InnoDB使用缓冲池来提高性能。InnoDB的数据存储都是以页为维度的,缓冲池中主要存放:
- 数据页
- 索引页
- undo页
- Change Buffer页
- 自适应哈希索引
- 锁信息
- 数据字典信息
- redo日志
(三)磁盘文件
InnoDB存储引擎是基于磁盘的,所有的数据都存放在磁盘文件中,后续会分析数据如何存储?
InnoDB存储结构
InnoDB中每张表都有主键,如果没有显示的定义主键,会选择一个非空的唯一索引来做为主键;如果没有,则自动创建一个6字节大小的指针做主键。
本篇文章基于的是MySQL5.7版本之后,因此一些弃用的特性就不介绍了,比如frm文件要来保存表结构元数据信息等。
下文通过InnoDB逻辑存储结构和物理存储结构综合来介绍,主要解决下面两个问题:
- InnoDB逻辑上是怎么组织数据的???
- InnoDB逻辑上设计的存储结构怎么落地到物理存储上的???
逻辑&物理存储结构
InnoDB中所有数据都被存放在一个空间中,称之为“表空间(tablespace)”;表空间又由段(segment)、区(extent)、页(page)组成。
先上图,InnoDB的逻辑存储结构如下图所示: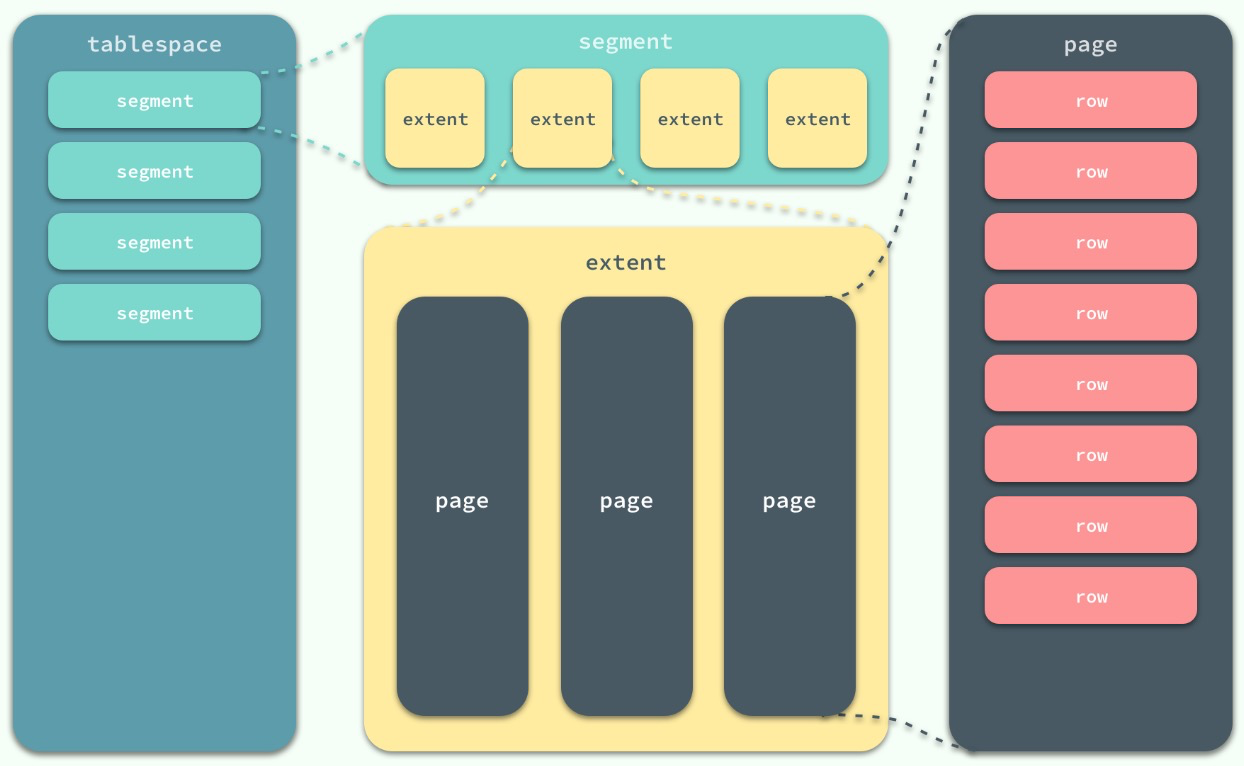
从图中可以看出,他们的层级关系是一对多,下面逐步介绍各个层级的逻辑结构!
1. 表空间——Tablespace
表空间可以看做是InnoDB逻辑存储结构的最高层级;所有的数据都是存放在表空间中的。默认情况下,InnoDB的所有数据都存放在共享表空间中ibdata1;当用户设置参数innodb_file_per_table时,InnoDB会为每个表产生一个独立的表空间。
独立的表空间中只存放数据,索引和Change Buffer;而其余的undo信息,事务信息,Double Write等还在共享表空间中。
(一)共享表空间
共享表空间又叫做系统表空间(System Tablespace),默认的文件名为ibdata1。可以通过innochecksum --page-type-summary ibdata1命令查看共享表空间中存放了哪些文件类型。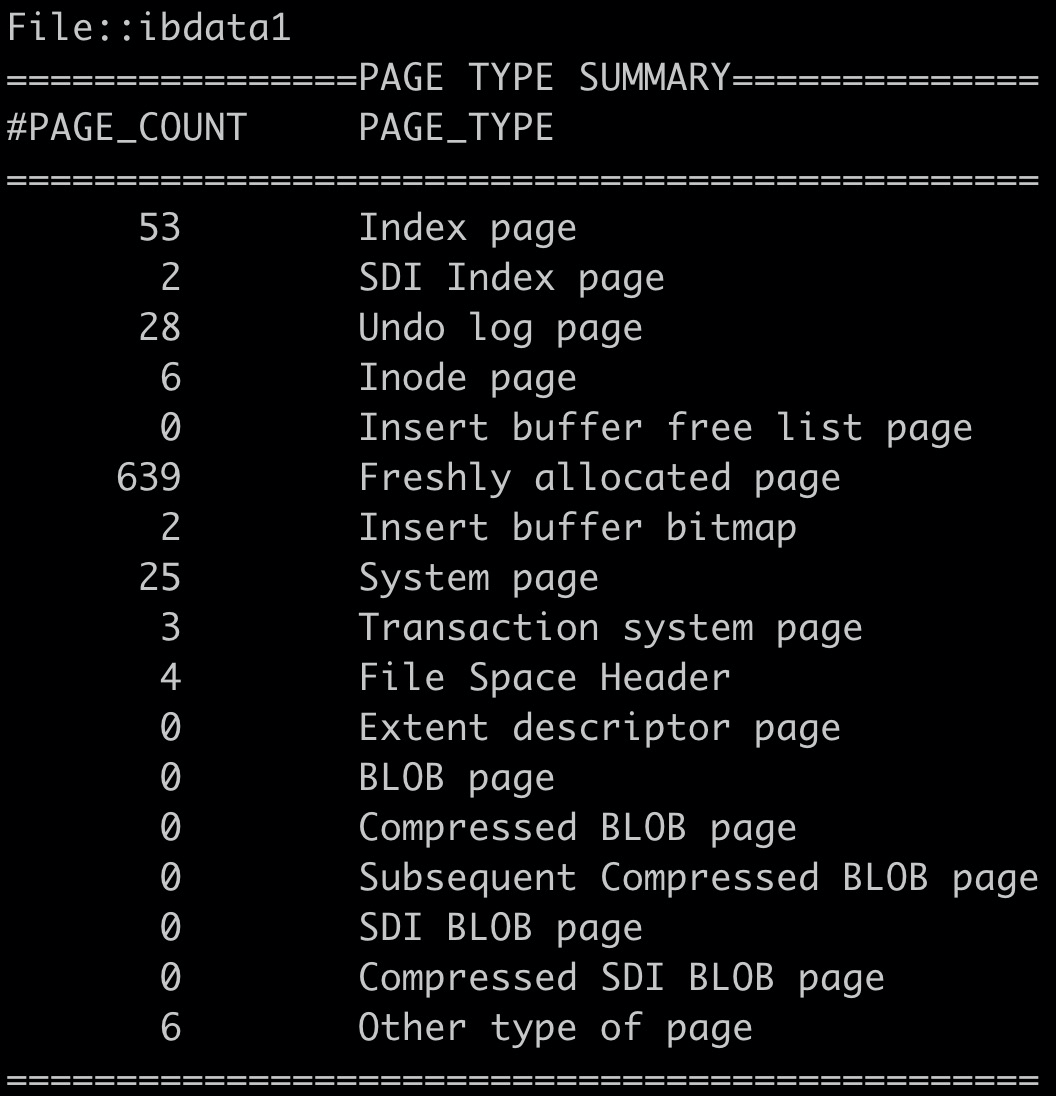
在innodb_file_per_table参数开启后,共享表空间中的数据页(data page)移到了独立表空间中。ibdata1文件的初始大小为12M,磁盘上的文件都是以二进制的形式存储。在ibdata1文件中顺序的存放着不同种类的page。
由于初始大小为12M,当保存的page信息增多时,共享表空间会继续生成新的文件来增长空间,比如ibdata2,ibdata3等等。当共享表空间暴增的时候会导致InnoDB的性能变差,那么何时会导致共享表空间大小暴增???
共享表空间中主要保存了undo信息和Change Buffer信息;因此大小暴增主要有下面两个原因:
- 大事务,产生大量的undo页;
- 索引建立过多,导致Change Buffer暴增;
解决办法
对于大事务的undo页信息,InnoDB提供了解决办法,可以在共享表空间初始化的时候讲undo页分离出去;参数innodb_undo_tablespaces可以设置undo表空间的个数,后续所有的undo信息会保存在单独的undo表空间中。
共享表空间存储结构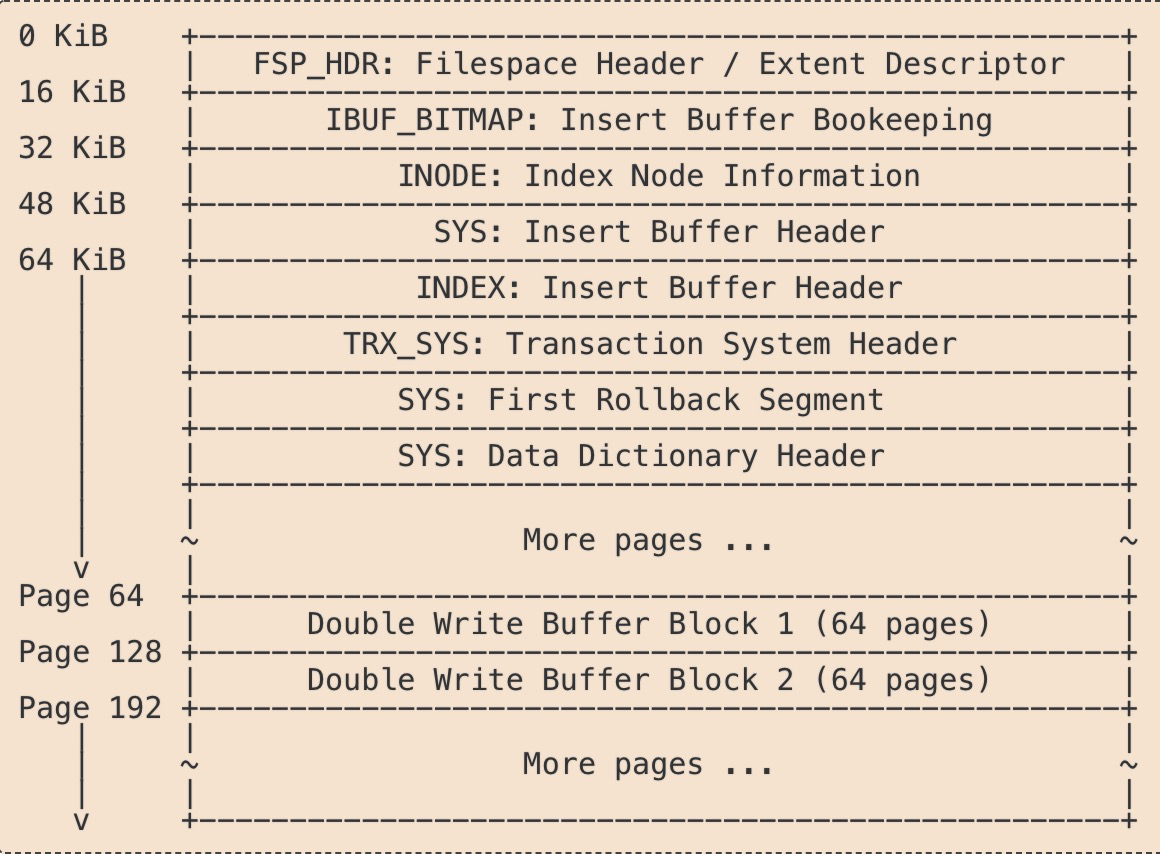
具体的字节的详细含义此处略过,大体的结构如图所示。
优点
表大小可以无限增大,可以跨文件存储,不同的文件可以存储在不同的磁盘上。
缺点
所有表的数据存放在一起,不易区分;当表删除回收后,会产生大量的空间碎片。
(二)独立表空间
基于上述共享表空间的缺点,InnoDB支持为每个表建立一个独立表空间文件,文件名为”表名.ibd”。
独立表空间存储结构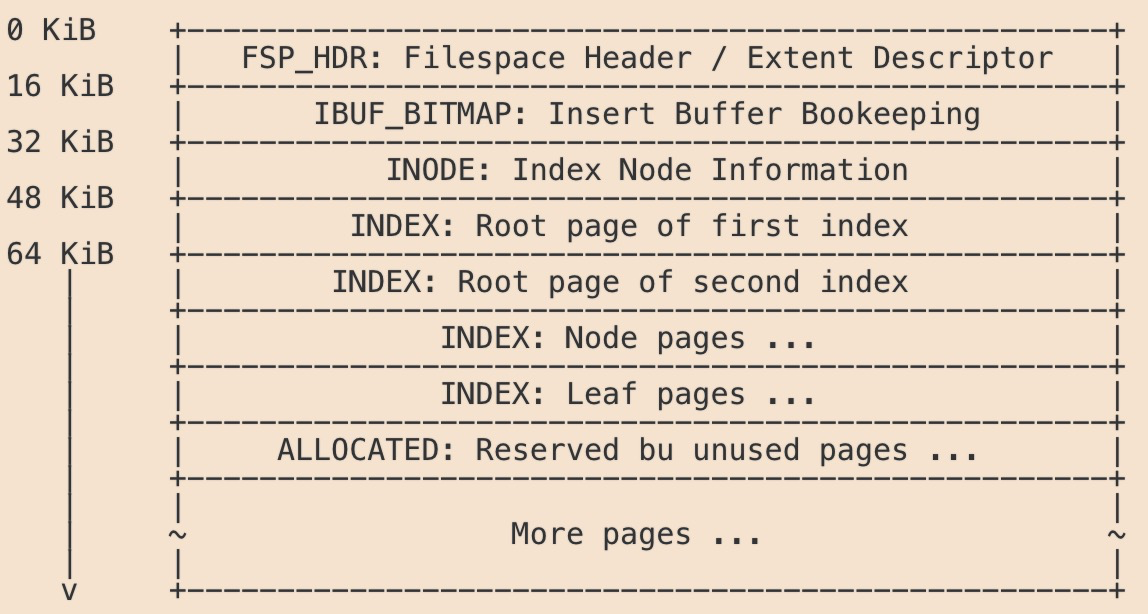
优点
每个表独立存储自身的数据和索引,方便不同数据库的迁移;表被回收后,不影响其他表;表内的空间碎片相对较少。
缺点
单表的空间增长过大会导致存储空间不足,需要从操作系统层面来解决。
2. 段——Segment
从逻辑结构图中可以看出,表空间包含多个段,其中最主要的是:
- 数据段:
B+树叶子节点; - 索引段:
B+树非叶子节点; - 回滚段:
用来事务回滚;
段存储结构
段在固定位置保存了区的元数据信息,其物理存储结构如下图所示: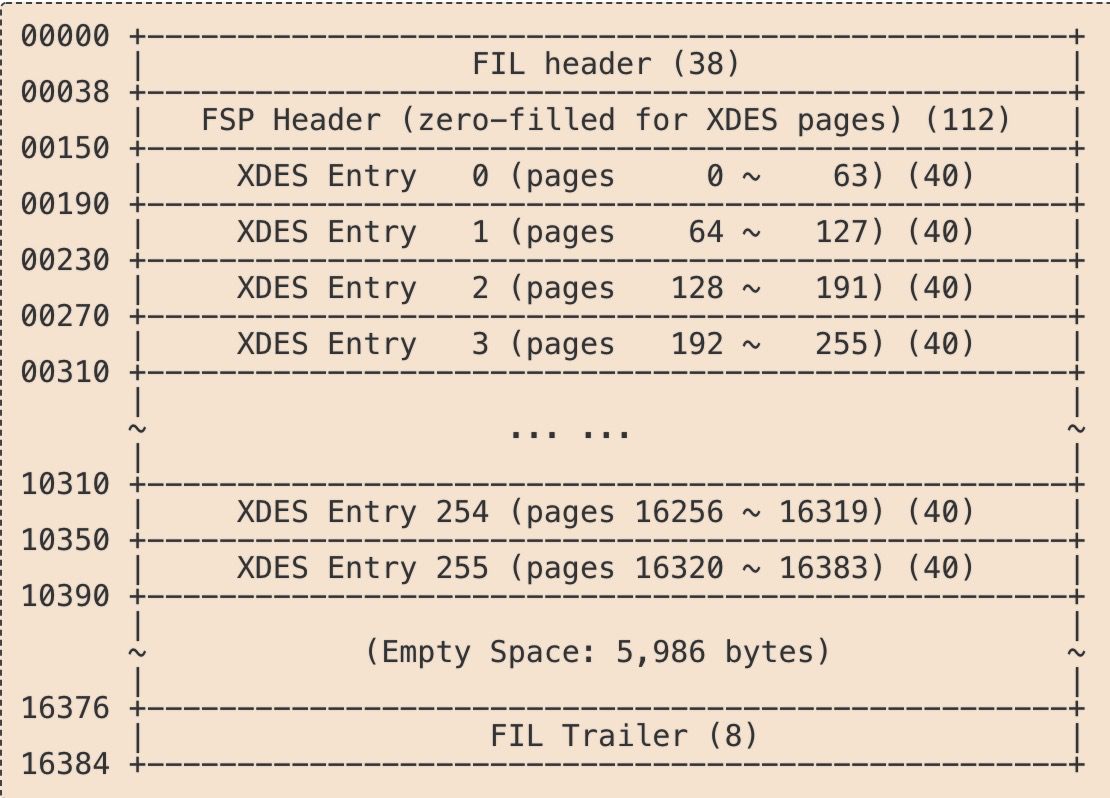
3. 区——Extent
区是由连续页组成的空间,为保证区中页的连续性,InnoDB会一次性的从磁盘申请4~5个区。区根据描述符来管理自身的页数据,其结构如下:
区存储结构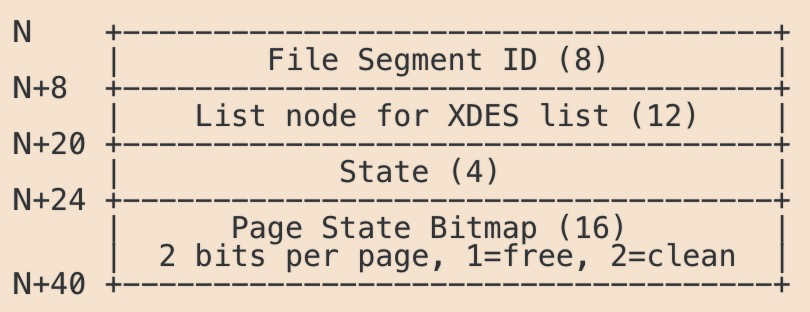
4. 页——Page
页是InnoDB最基本的结构,也是磁盘管理的最小单位。页主要有以下几种:
- 数据页
- 索引页
- undo页
- 系统页
- 事务数据页
这边主要讲解数据页和索引页,不说废话,先上图:
页存储结构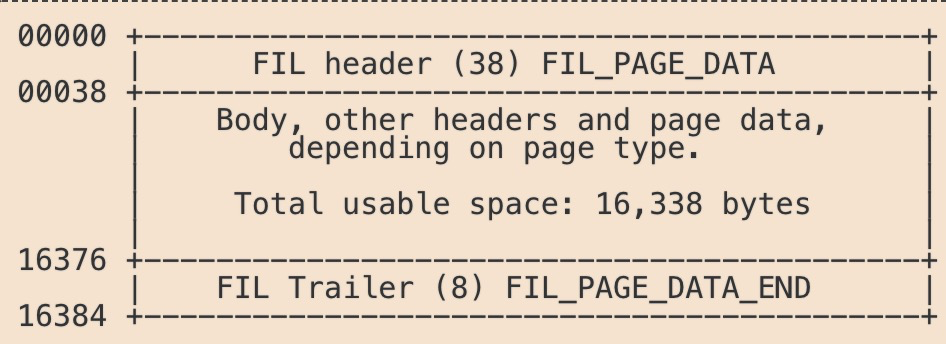
页主要包含页头(38个字节),页尾(8个字节)以及中间的body,这很类似网络中包的结构,页头中包含了页的基本信息,页尾中包含了页数据的一些校验,下面看下页头和页尾的具体结构:
页头页尾存储结构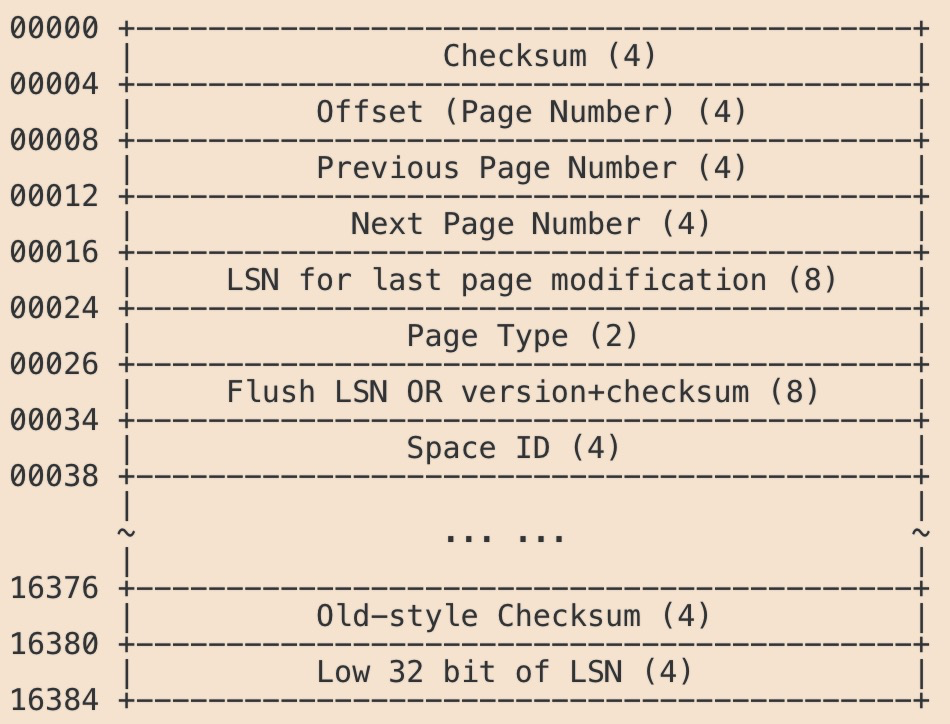
从页头中发现,每个页都有一个int类型唯一的id,代表页的偏移量,由于int类型4个字节,这也导致了页最大为64TB($2^{32}$);此外页头中还包含两个重要的指针:Previous Page Number和Next Page Number,分别指向前一页和后一页,这样我们就知道了,在一个B+树的节点里,不同的页是通过链表来顺序遍历的;页尾主要用于数据一致性校验,checksum来检查数据的完整性。
头尾的存储都介绍完毕了,就剩下body存储数据,数据都是以行(Row)记录的形式存储;由于页内部空闲空间是随机分配的,以链表来组织,因此需要界定下记录的开始和结尾,因此body的部分一开始有两个系统定义的头尾记录指针:infimum和supremum,用来保存记录的首尾,其结构如下图所示:
记录首尾存储结构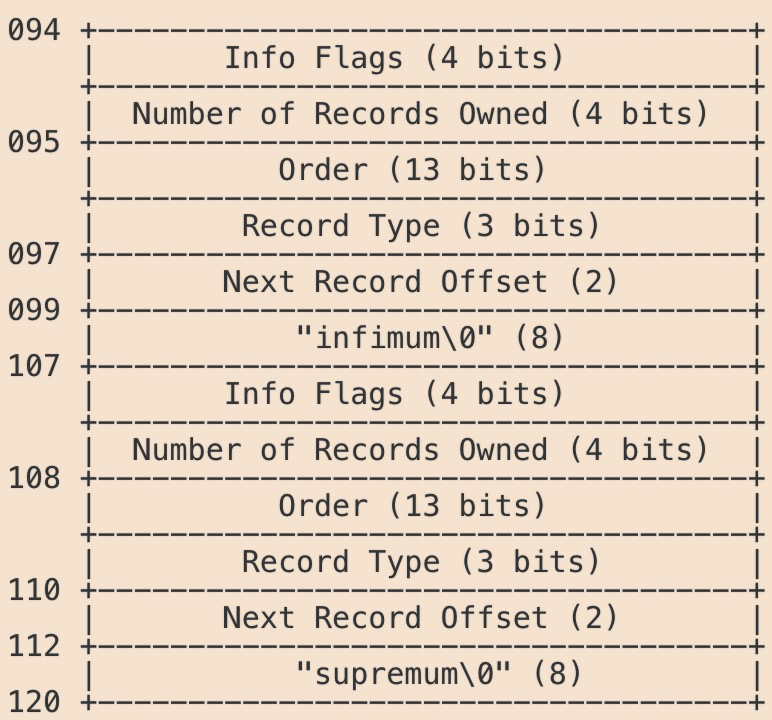
infimum记录从094开始,依次到120以supremum结束。那038到094之前存储什么信息???
主要存储的是索引头的信息,因为InnoDB中数据以B+树的形式存储。
记录首尾相连的格式如下图: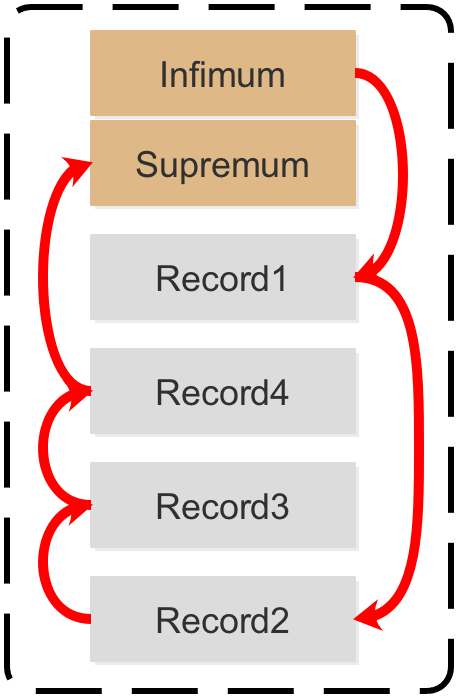
索引头存储结构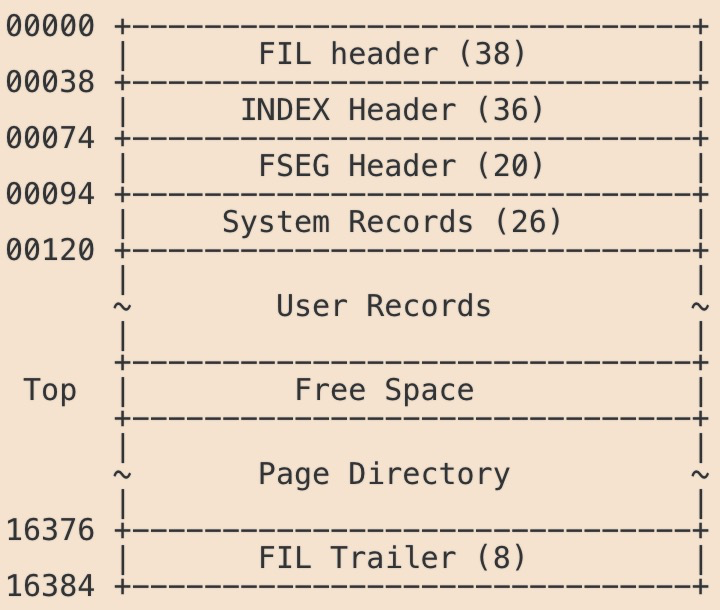
里面的信息不详细展开了。
5. 行——Row
千呼万唤始出来,绕了半天,终于讲到了行(Row)记录的存储结构;InnoDB支持不同类型的行格式来存储数据,如下图: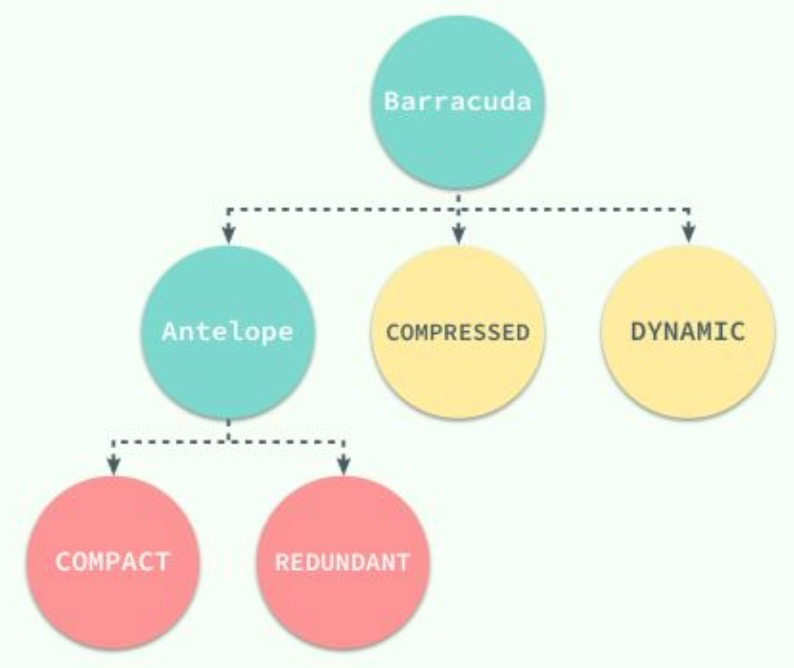
其中Antelope是文件最开始支持的形式,后续增加了Barracuda的格式;其中最常用的是Compact,下面主要介绍Compact格式。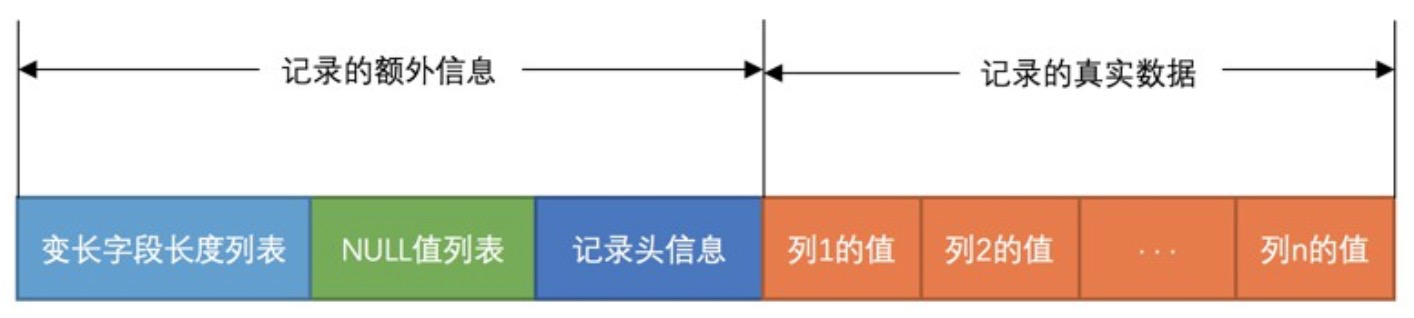
下面分析下各个字段的含义:
- 变长字段长度列表:
主要用来存放变长字段的长度,逆序排列。举例: 字段VARCHAR(16),存储”abc”,则变长长度为03;把所有变长字段的长度逆序排列;
- NULL标志位:
标志列是否为null; - 记录头信息:
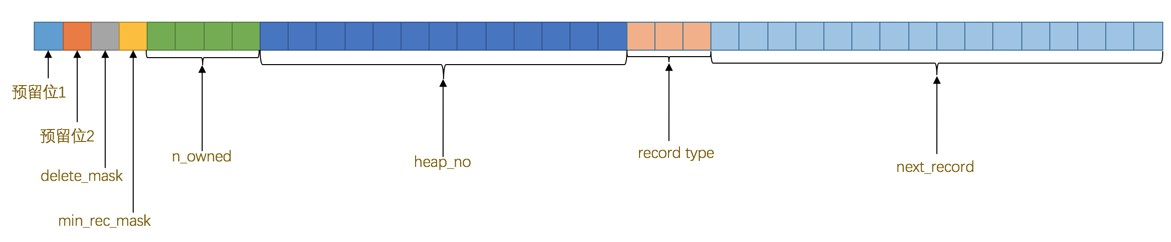 > record_type记录类型,3bit,000表示普通页;001表示B+树节点;010表示infimum;011表示supremum;1xx保留。
> record_type记录类型,3bit,000表示普通页;001表示B+树节点;010表示infimum;011表示supremum;1xx保留。 - 列值:
真实的数据;InnoDB会为每行数据添加隐藏的三个列值:
- DB_ROW_ID 行ID,唯一标识一条记录;
- DB_TRX_ID 事务ID;
- DB_ROLL_PTR 回滚指针;
由于页有大小限制,当数据库中存储TEXT,BLOB等大型数据时,上述的列值不能完整的存放下所有的数据,这个时候怎么办???
InnoDB会生成一个BLOB的新页,然后在该列值上存放新页的地址来指向它。Compact格式会存储开头的768bytes。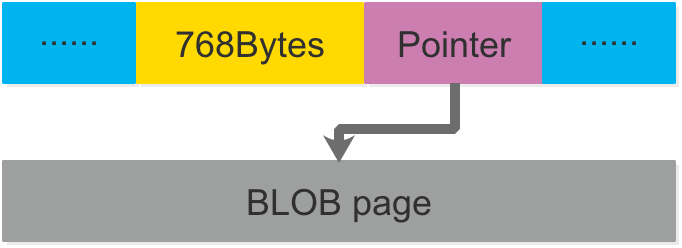
总结
本文主要介绍了InnoDB存储的逻辑结构和物理结构;说白了就是在文件中用链表实现了B+树;为了让计算机识别二进制数据,在记录的头部和尾部包装了各式各样的元信息;为了便于InnoDB各种关键特性的实现,又将头部尾部的元信息分层:segment,extent,page,row。
逻辑结构和物理结构的映射如下图: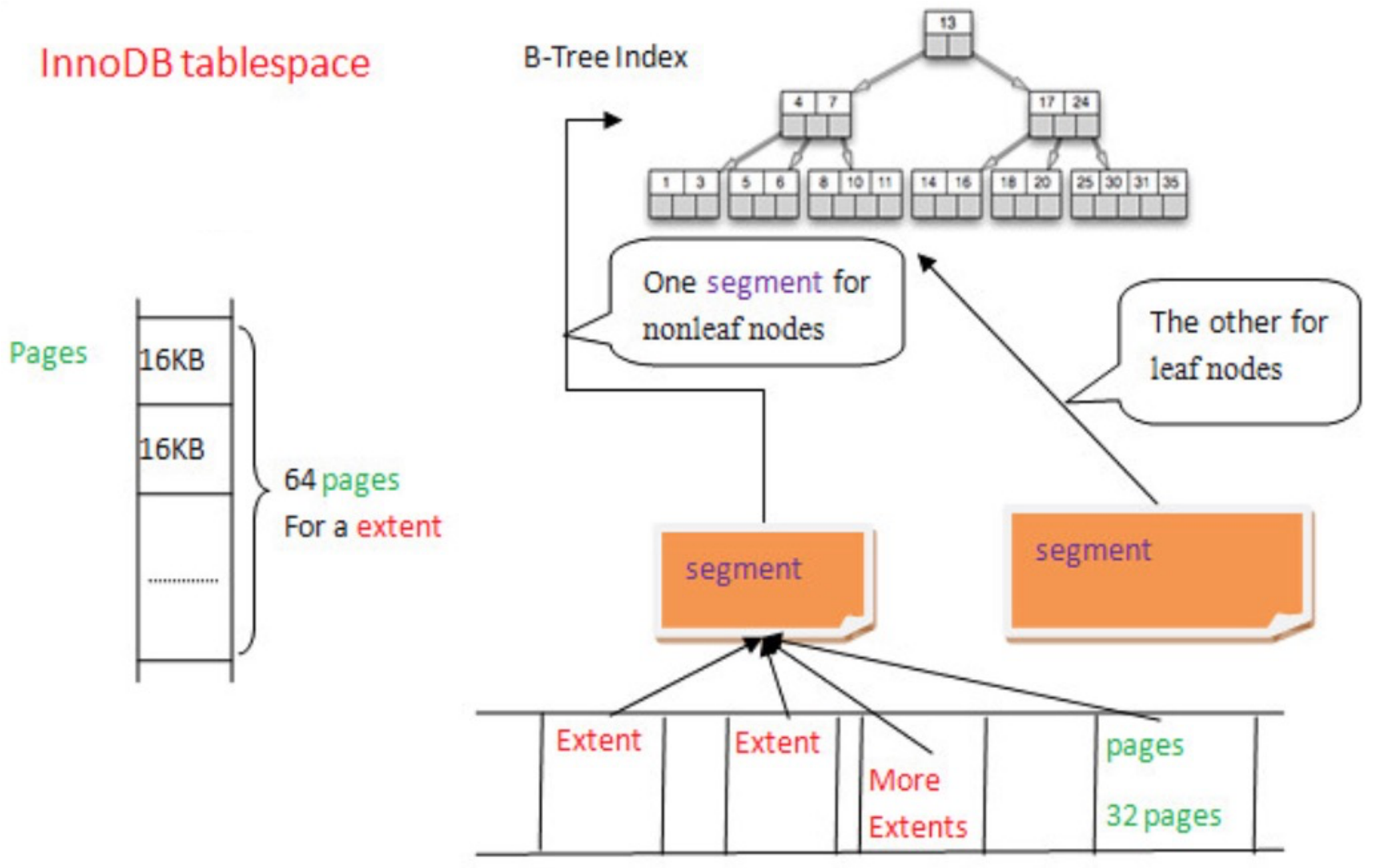
参考
[1] MySQL技术内幕:InnoDB存储引擎
[2] MySQL官方文档
[3] 博客

